最近把一堆关于 Agent / Harness Engineering 的技术分享整理了一遍,发现一个特别清晰的线索——2023 到 2026 这四年里,AI 工程的"调教对象"发生了三次跃迁。而且这三次跃迁不是词汇升级,是问题维度的升级。
本文记一下这条主线、以及它背后的两个硬事实。
三级跃迁:同一张表
这张表最近在很多技术分享里反复出现,基本可以当作行业共识:
| 2023 | 2024–2025 | 2026 | |
|---|---|---|---|
| 范式 | Prompt Engineering | Context Engineering | Harness Engineering |
| 在调教什么 | 一句话 | 上下文 | 整个系统 |
| 期望效果 | 模型听话 | 模型懂项目 | Agent 可控 |
| 可调对象 | Prompt 文本 | CLAUDE.md / AGENTS.md / SKILL.md | 循环 / 工具 / 权限 / 上下文 / 成本 |
左边的问题是"这句话怎么说更好",中间的问题是"模型应该看见哪些信息",右边的问题完全不一样了——
整个系统应该怎么运行,才能保证模型在几小时、多轮、多工具、多会话的条件下,仍能稳定交付结果?
这不再是对话问题,是系统工程问题。
为什么会发生这次跃迁?
两个硬事实推着它发生。
事实一:从 L1 Chatbot 到 L3 Agent,单次 Token 消耗涨了 100 倍
业界一组被多次引用的数据:
| 级别 | 代表 | 单次 Token 消耗 |
|---|---|---|
| L1 Chatbot | ChatGPT 3.5 | 500 ~ 2000 |
| L2 Reasoner | OpenAI o1 / o3 | 5k ~ 50k |
| L3 Agent | Claude Code 等 | 20k ~ 200k+ |
| L4 Innovator | —— | 1M 以上 |
Token 消耗不是"模型更贵了",而是"服务模式变了"——从"单次直觉问答"变成了"深度思考 + 迭代探索"。
当一次任务要跑 20 万 Token、要调用几十次工具、要跨越几个小时,任何一步出错都可能导致整件事从头开始。这时候你不能再靠"把规则写进 Prompt"来控制它——你得在模型外面套一层确定性的系统。
事实二:改壳不改模,性能可以翻倍
几个很扎心的数字:
- Nate B Jones:仅更换 Agent Harness,编程基准 42% → 78%
- LangChain(Terminal Bench 2.0):优化 Harness 后,分数 52.8% → 66.5%,排名从第 30 跃升到前 5
- LangChain Deep Agents(2026 年 3 月):同模型、同 Benchmark,仅调 Harness,分数提升 13.7 分
- Vercel:工具数量从 15 砍到 2,准确率 80% → 100%
最直接的一句话总结来自 Anthropic:
Agent performance is dominated by harness design.
以及 Martin Fowler 更短的版本:
The agent is the system, not the model.
这三次跃迁具体差别在哪?
把"可调教对象"这一列展开看,能看出问题维度真的在升级:
| 可调教对象 | 调教者 | 反馈环路 | 失败代价 | |
|---|---|---|---|---|
| Prompt | 文本 | 人类 | 人工试错 | 输出不好 |
| Context | 上下文窗口 | 人类 | 人工 + 检索 | 幻觉 / 遗忘 |
| Harness | 循环 / 工具 / 权限 / 成本 | 人类 + 工具 | 自动化测试 + 指标 | 失控 / 超支 |
| Evolution(未来) | 约束本身 | Agent(人类监督) | 自动化 + 自我评估 | 约束漂移 |
有几个点值得单独拎出来。
1. “失败代价"在变
- Prompt 时代,失败代价是"这次回答不好”
- Context 时代,失败代价是"幻觉 / 遗忘"
- Harness 时代,失败代价直接变成了 “失控 / 超支"——Agent 会真的删掉文件、真的发送邮件、真的烧掉几百刀 Token
这就是为什么 Harness 层必须引入权限最小化、循环有界、审核不可跳过这些控制论概念。
2. “反馈环路"在自动化
前两代的反馈闭合点都是"人类”——写完 Prompt 人工试一下、看看 Context 够不够。
Harness 时代的反馈环路里必须有自动化验证层,因为 Agent 一跑可能是几小时到几十小时,没有自动化反馈根本来不及介入。所以你会看到 Anthropic 的三 Agent 架构里有一个独立的 Evaluator,Stripe 的 Blueprint 里最多允许 CI 跑两轮自动修复,Cursor 每小时 ~1000 个 commit 背后全是自动化 QA。
3. “可调教对象"在扩张
Prompt → Context → Harness 的路径,其实是把原来藏在人脑子里的决策一个个地"物化"出来:
- “我希望模型这样回答” → 写成 Prompt
- “我希望模型了解这些背景” → 塞进 Context
- “我希望模型按这个流程工作、不越权、出错能回滚、花钱不超预算” → 写成 Harness
每一次物化都让系统变得更可观测、更可控、也更能被多个人协作维护。
Harness 到底长啥样?
Harness ≈ 模型外面的操作系统。
如果用"计算机四件套"类比:
| 类比 | 对应 |
|---|---|
| CPU | Model(算力与决策) |
| 内存 | 上下文窗口(短时工作区) |
| 操作系统 | Harness Runtime(资源管理、进程调度、约束、I/O) |
| 应用程序 | Agent(跑在"AI OS"之上的具体智能体) |
一个生产级 Harness 至少包含五个子系统:
- Environment:受控的工作世界(沙箱 / 文件系统 / 终端 / 浏览器)
- Tool System:对能力做抽象封装(
read_file/write_file/run_test/search_code) - Control:管 Agent Loop 的执行边界(步数 / 时长 / 权限 / 错误处理)
- Memory / State:管长任务、跨会话的状态(progress file / feature list / Git)
- Evaluation:让系统自己知道做得好不好(测试 / Linter / 自动化 UI 检查 / 二模型打分)
一句话:模型决定能力上限,Harness 决定系统稳定性。
为什么 Demo 惊艳、上线即崩?
绝大多数 Agent 项目 Demo 到生产的断崖,本质不是"模型不够强”,而是下面这些事在 Demo 里可以不做、在生产里做不到:
| Demo 能跑是因为… | 生产里必须要有的东西 |
|---|---|
| 任务很短,一次就完 | 显式状态机 + Checkpoint,中断能恢复 |
| 错了重试几次就好 | 错误分类 + 分层恢复(临时错重试、逻辑错交回 Generator、权限错直接 fail) |
| 反正也不花几毛钱 | Token / 步数 / 时长的硬预算,不依赖模型判断"该不该停” |
| 自己看一眼就知道做得对不对 | 独立的 Evaluator,不让模型自评 |
| 错了我知道在哪 | 完整日志 + 可观测,失败能定位到第几步开始偏 |
这五件事,没有一件需要更强的模型。它们全部是"模型外面的工程活"。
一个有控制论味道的类比:第三次"反馈回路上移"
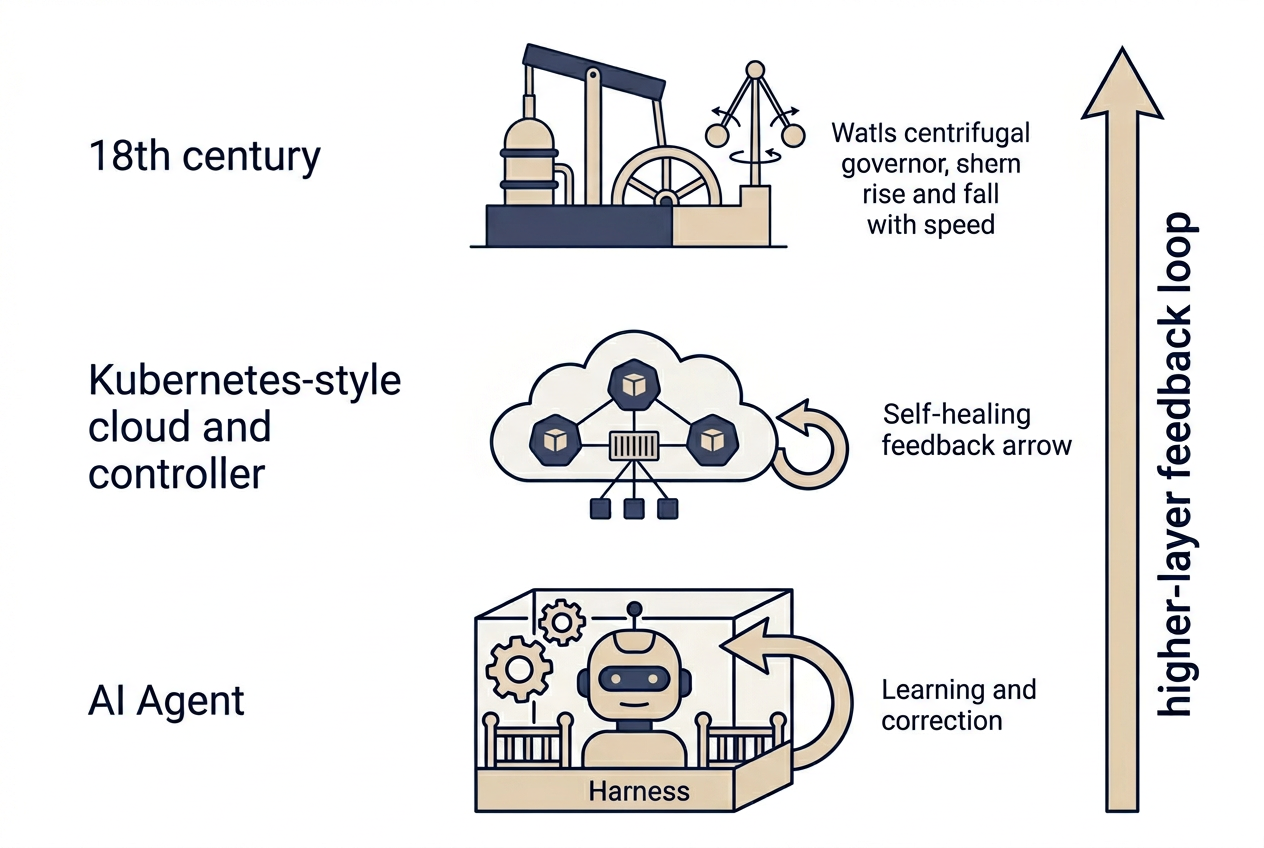
Harness 的本质其实很古典——就是控制论。
历史上这样的跃迁发生过两次:
| 时代 | 系统 | 变化 |
|---|---|---|
| 18 世纪 | 瓦特离心调速器 | 工人从"实时拧阀门" → 设计调速器,系统自动调节 |
| 2010s | Kubernetes 控制器 | 工程师从"手动重启 / 扩容" → 声明期望状态,K8s 自动对齐 |
| 2026 | Harness Engineering | 工程师从"逐步提示 Agent" → 设计环境 / 约束 / 反馈回路,Agent 自动运行 |
每一次跃迁的共性是:反馈回路在更高一层闭合,人的工作从"亲手调参"变成"设计控制系统"。
传统软件早已在多层闭合反馈:编译器 → 语法、测试套件 → 行为、Linter → 风格。但架构决策和长期演化这一层,过去一直没有自动反馈。
大模型首次让这一层的反馈闭合成为可能。但要真的闭合,必须由 Harness 提供传感器(文档、依赖图、测试报告、监控指标)与执行器(代码修改权限、重构工具、CI/CD)。
给自己的三个行动启发
对照这条主线,我给自己列了三个问题:
1. 我正在做的 AI 应用,处在哪一代?
- 如果还在"这句话怎么写更好",那是 Prompt 级
- 如果在调
AGENTS.md/CLAUDE.md/ RAG 检索,那是 Context 级 - 如果开始设计"Agent 跑多久必须停、哪些工具能用哪些不能、出错怎么回滚、预算怎么管",那才是 Harness 级
不是越靠后越好,是要匹配你的任务复杂度。单轮问答不需要 Harness,长周期多工具任务没有 Harness 必崩。
2. 我的哪些"规则"还写在 Prompt 里?
一个很好的自查动作是:把当前 Agent 的系统 Prompt 打开,看里面有没有这类话——
- “请不要删除文件”
- “谨慎调用此接口”
- “如果不确定就问我”
凡是能用确定性机制表达的约束,就不要只写在 Prompt 里。百步长任务中,Prompt 级约束的概率性违约几乎不可避免。把"不许"换成 sandbox + allowlist,把"谨慎"换成 tool 级审批,把"不确定就问"换成状态机里的 WAITING_HUMAN 状态。
3. 我有没有在自动化反馈这一层投入?
Harness 时代的分水岭不是"你用不用 Agent",是——
你敢不敢让 Agent 在无人值守的情况下跑几个小时。
敢不敢,取决于:
- 有没有状态机 + checkpoint 能中断恢复
- 有没有独立 Evaluator 判断"做得对不对"
- 有没有 token / 时长 / 步数预算防止失控
- 有没有日志让你能复盘 Agent 在第几步走偏的
只要这四个里有一个没有,答案就是不敢。敢不敢无人值守,就是 Prompt 级和 Harness 级的真实分界线。
小结
- Prompt Engineering 调的是一句话,Context Engineering 调的是上下文,Harness Engineering 调的是整个系统。
- 每一次跃迁的核心都是把原本藏在人脑里的决策物化出来,让反馈回路在更高一层自动闭合。
- 模型能力过剩不是 Harness 的终点,反而是 Harness 的起点——引擎越强,护栏越重要。
- 这不是理论讨论。改壳不改模,编程基准可以从 42% 跳到 78%,单这一条数据就值得把 2026 年的工程注意力向 Harness 侧重倾斜。